solr4.7中文分词器(ik-analyzer)配置
本文共 907 字,大约阅读时间需要 3 分钟。
solr本身对中文分词的处理不是太好,所以中文应用很多时候都需要额外加一个中文分词器对中文进行分词处理,ik-analyzer就是其中一个不错的中文分词器。
一、版本信息
solr版本:4.7.0
需要ik-analyzer版本:IK Analyzer 2012FF_hf1
ik-analyzer下载地址:
二、配置步骤
下载压缩解压后得到如下目录结构的文件夹:
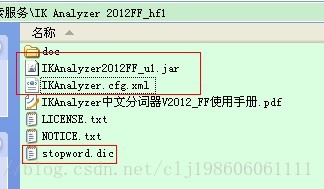
我们把IKAnalyzer2012FF_u1.jar拷贝到solr服务的solr\WEB-INF\lib下面。
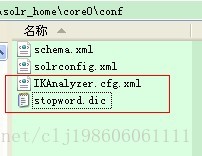
我们把IKAnalyzer.cfg.xml、stopword.dic拷贝到需要使用分词器的core的conf下面,和core的schema.xml文件一个目录。
修改core的schema.xml,在<types></types>配置项间加一段如下配置:
我们就多了一种text_ik的field类型了,该类型使用的分词器就是。
我们在这个core的schema.xml里面配置field类型的时候就可以使用text_ik了。
三、中文分词测试
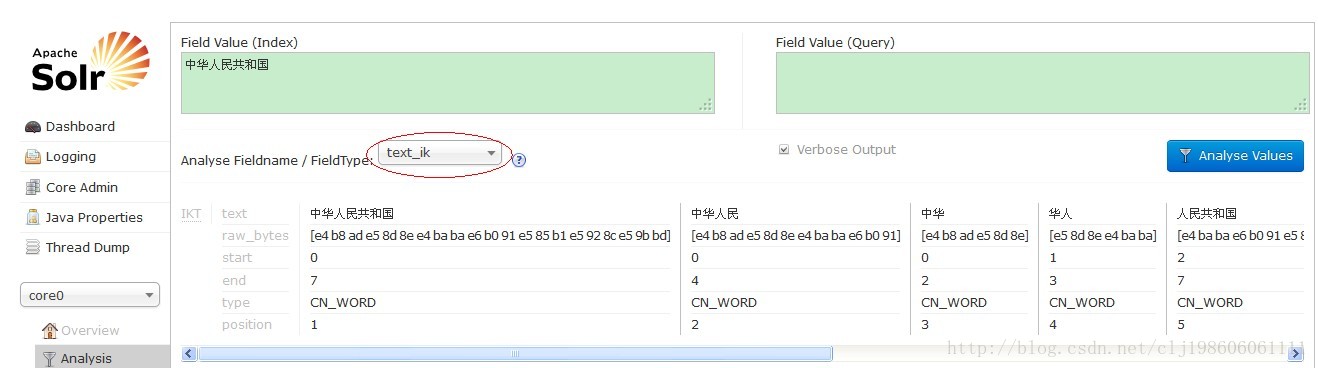
IKT textraw_bytesstartendtypeposition 中华人民共和国[e4 b8 ad e5 8d 8e e4 ba ba e6 b0 91 e5 85 b1 e5 92 8c e5 9b bd]07CN_WORD1 中华人民[e4 b8 ad e5 8d 8e e4 ba ba e6 b0 91]04CN_WORD2 中华[e4 b8 ad e5 8d 8e]02CN_WORD3 华人[e5 8d 8e e4 ba ba]13CN_WORD4 人民共和国[e4 ba ba e6 b0 91 e5 85 b1 e5 92 8c e5 9b bd]27CN_WORD5 人民[e4 ba ba e6 b0 91]24CN_WORD6 共和国[e5 85 b1 e5 92 8c e5 9b bd]47CN_WORD7 共和[e5 85 b1 e5 92 8c]46CN_WORD8 国[e5 9b bd]67CN_CHAR9
你可能感兴趣的文章
PDF 翻译神器,再也不担心读不懂英文 Paper 了
查看>>
漫话:如何给女朋友解释什么是RPC
查看>>
情人节她说:是的,嫁人当嫁程序员
查看>>
不要成为自己讨厌的那种程序员 | 程序员有话说
查看>>
为什么程序员下班后只关显示器从不关电脑?
查看>>
滴滴裁员 2000 人,具体补偿方案已出
查看>>
余生,做个不焦虑的程序员!
查看>>
世界排名第 3 的滴滴裁员,开春求职必知的独角兽排行榜
查看>>
Spring Boot 中的响应式编程和 WebFlux 入门
查看>>
如何从零开始两天撸一个微信小程序?!(内含源码)
查看>>
女神?御姐?文艺?这样的程序媛你绝没见过! | 程序员有话说
查看>>
“软件外包城”下的马鞍山 | 程序员有话说
查看>>
那些上相亲网站的程序员,后来怎么样了?
查看>>
程序员如何实现财富自由?
查看>>
你我的父母,都在被互联网“割韭菜”
查看>>
程序员下班后都忙些啥?| 程序员有话说
查看>>
万万没想到你们竟是这样的程序员 | 程序员有话说
查看>>
Java 帝国对 Python 的渗透能成功吗?
查看>>
从培训机构出来的程序员,后来都怎么样了? | 程序员有话说
查看>>
程序员写代码没激情该怎么破?
查看>>